Hi everybody, I been making this project for quite sometime now using static cameras, but now I’m trying to rotate it in using joints (i m using gazebo fortress and ros2 humble, although I tried different ros and gazebos combinations but without success).
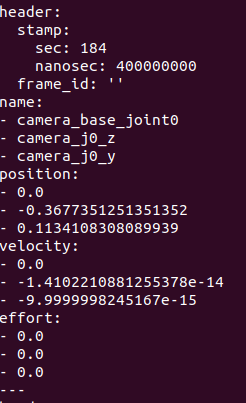
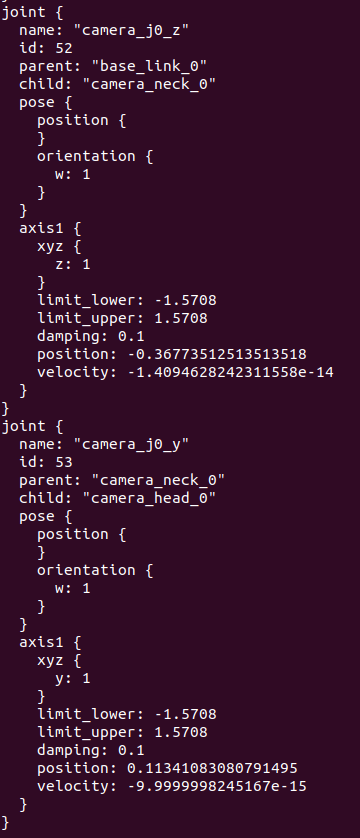
For now i’m trying to use the joint state publisher, with ros_gz_bridge i’m able to subscribe to the topic and visualize the joints positions that i’m controlling inside gazebo using the joint position control.
The ros2 topic echo
What I need is a way to control the camera’s joints via ROS2 code (python), and I just don’t know how to publish the message, if anyone has any ideas or if I need to take a course or something, I would be grateful
There are two ways with which you can accomplish your task.
But before that, this is what I understand when you say “static cameras”. The x, y, z coordinates of the camera are going to be fixed, while the camera is able to pan and tilt (rotate in 2 or 3 axes).
Please let me know if my understanding is wrong.
The first way is to make your camera itself as a robot and disable gravity. This way you can control the camera rotations just like a robot.
The second way is to again define the camera links by disabling the gravity. You can then use gazebo model state commands to move (rotate) the camera as per your needs. This is done by publishing model pose to the gazebo sim topics/services.
The advantage with the first method is that you can control the camera with ROS2 directly.
The disadvantage with the second method is that you need to write a program code to communicate with gazebo topics and ROS2 topics. This is done without using ROS-GZ bridge.
Have you tried using the “Follow” command with your robot on Gazebo Sim?
If you are trying to follow the robot movement, then what you can otherwise do is to make a “follow-camera”. You can do this simply by right clicking on the robot entity on gazebo and selecting “Follow”. This is to automatically focus the camera onto the robot when the robot moves in gazebo sim.
Thank you for the reply @girishkumar.kannan! That’s correct, the cameras only rotates. But let me be more specific: I’ve done a system which the cameras detects the robot using yolo v8, and using the cameras pose plus the x and y coordinates of the image detected i’m basically able to estimate the robot x and y pose (with some error of course), but I have to make sure that the robot is precisely in the center of the camera image.
So i believe that the first method is more suitable for me because I’m used to use the ros-gz-bridge, but I’m curious about the second one.
I just tried the follow option but it only makes the camera gui follow the robot, i might try again later
Now I understand your idea better. Thanks for providing more context.
For simulation purposes, you can make use of TF lookup methods to make the cameras always follow the robot’s base link frame. But of course, this is not a viable solution if you are considering real-time environment.
That’s true. But now that you have stated the purpose for your cameras, I believe that this is not a good option for you.
Hi @girishkumar.kannan i took a look in the tf2 and how it might work in the ros2 documentation, but I believe it would be cheating
I have to explain a bit more, this is a project based on my teacher’s phd thesis (here is his article: http://arxiv.org/pdf/2011.01397) and the first step was to recognize the robot via some kind of image recognition algorithm, he used color segmentation, long story short, i want to prove that his project works for basically any robot. I’m almost there, but I’m really stuck trying to make this cameras to rotate, so i think my only option would it to make a robot just like you said in here right?
Would i have to make a urdf? But would i be able to spawn in gazebo so i can visualize the robots movement with my robot (and to this case I would spawn 3 since I’m using 3 cameras), or is it simpler if I do this ALL on rviz?
Haha, yes, you’re right. That’s why I did not emphasize that point much.
It is not exactly your only option, but the first option that I gave you is easier and faster compared to the second one which involves communicating between Gazebo and ROS which increases communication time 2x.
Yes, you will have to make a URDF for this camera and most importantly, disable gravity for all associated links for this camera (robot).
I would not suggest that you spawn the camera. Rather try to add it to the world model as a static model (I have not done this before, so I do not know if this is a good or bad choice).
You can visualize all the 3 cameras along with your main robot on RViz if you link the cameras and robot to a global refrence frame such as world or map (definitely not odom for obvious reasons).
I did take a glimpse through the paper and the conclusion, I did not read through the entire pages. I can give you some CV based ideas to make your detection and tracking algorithm converge faster. Let me know!
Let us start with the above line specifically. You want to make a general robot detection algorithm. The more general you get, the more noisy or rough your results will be.
If you plan to detect and track humanoids, in a group of robots it will be faster. Same with quadrupeds or quad-rotors or 4-wheel mobile robots. But in a situation where you have a group of robots, trying to detect and track all the types in will have quite some noise to the whole process.
Now comes the question about the scene. Are the robots always going to be moving? If so how fast or how slow? If it is too slow, you might end up detecting non-robot objects. If it is too fast, you might miss tracking the robot at certain speeds.
So now let’s imagine the case you have portrayed in the simulation image you posted above.
You have a 4-wheel robot that has some color. Now if you want to implement a detection and tracking mode for this kind of robots, you can do something like below.
Here is a sample CV process that can make things faster.
Pyramidal down-sampling to reduce the resolution of the camera-acquired image to a process friendly resolution. You can’t process 1080p images at a fast rate if you have limited hardware capability.
Use Optical Flow method to find the moving robot location and to segment it.
Use 8-bit RGB color palette to down-quantize 24-bit RGB color. This will make detection faster and easier. 8-bit RGB provides 256 colors whereas 256 bit RGB produces 16 million colors which is very difficult for processing. You can then use the image for color based tracking.
You can also implement edge-detection algorithms onto the output from optical flow segmented images fine tune the segments.
You can then pass the resultant image into a neural network to draw the bounding boxes. If the image that is sent to the neural network is fine tuned well enough, the result that you get from the network will be more accurate and quicker.
You need to play-around with the sequence and combinations to get the result as you expect. So the above list of processes are not in any particular order.
Also, try to implement a buffered process pipeline. If you do all the image processing in sequential manner, your output will be slower than expected.
Try not to use a neural network (NN) as the first step. If the NN is properly configured and learned, you can get good results. If you are trying to use a general purpose model, your results won’t be good enough. You will have misdetections, process breakups and disconnected results.