In the course “Reinforcement Learning for Robotics”, chapter 2. The Bellman Equations in 2.6.4 for the state-value (V(s)) and the action-value (Q(s, a)) are exactly the same, is that right?
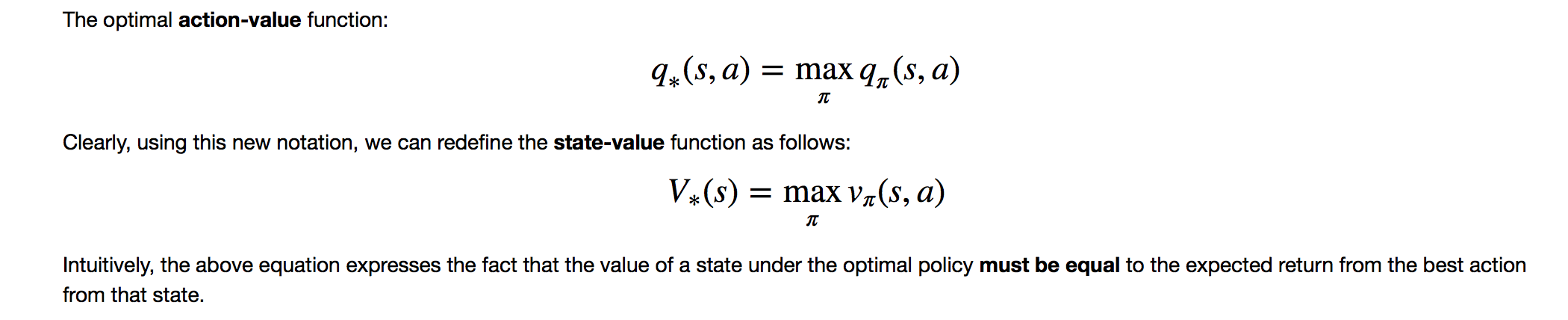
Hey, Thanks for your response.
I mean these two equations:
- Bellman equation for state value function:
- Bellman equation for state-action value function
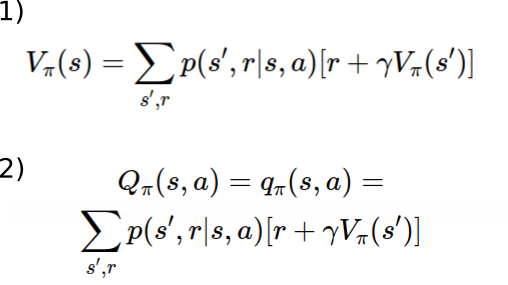
The right side of both bellman equations are exactly the same, I don’t think that’s the case. The first one looks weird to me. Maybe I’m wrong here.
Hello @Gaoyuan123 ,
Apologies for the late response, I totally missed your reply. My bad. Let me tell you that you were right and there was an error in these functions. I have just updated the notebook in order to fix it.
The state value function (V-function) alone can provide information about the desirability of different states in a Markov Decision Process (MDP), but it lacks the granularity of action-specific insights. While the state value function is useful, it cannot be used standalone for decision-making in scenarios where actions matter.
So, in many scenarios, state value function is combined with Policy Function. The policy function defines the strategy or behaviour of the agent by specifying which actions to take in each state.
The the actual equation is, as under and it is not alone the state value function but a policy function derived from state value function.
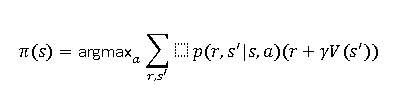
In many cases, such as actor-critic algorithms, state value function is used with policy gradient methods. In Proximal Policy Optimization (PPO), the advantage function has both state value and action value functions.
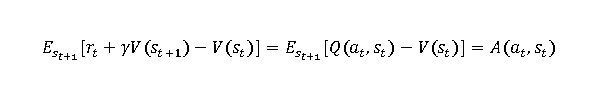
1 Like