I m in the stage in where i would like to monitor the training with the tensor board.
I m reducing the batch size and the epoch (just for the sake of seeing if the tensor board is able to monitor the loss functions for train and test.
python scripts/train.py
–dataset ./data/train.tfrecord
–val_dataset ./data/test.tfrecord
–classes ./data/train_new_names.names \ —> NOT new_names.names
–num_classes $num_new_classes
–mode fit --transfer darknet
–batch_size 3
–epochs 2
–weights ./checkpoints/yolov3.tf
–weights_num_classes $num_coco_classes
by the way in the jupiter notebook it mentions : data/new_names.names
and in fact calling the script:
generate_tfrecord_n.py --image_path_input=images/train --csv_input=data/train_labels.csv --output_path=data/train.tfrecord --output_path_names=data/train_new_names.names
However, this is not the issue for me.
Quote:
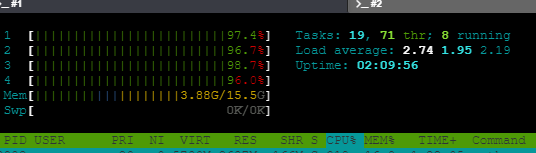
“You can also monitor the system load by executing top or htop (this last one has more colours). Here you can see the load average and the RAM memory used. Exceeding the RAM will terminate the system, so be carefull to not exceed the 95%.”
to avoid this i tried to reduce the number of training data by reducing the number of inputs of the training in the csv file “train_labels.csv”. This means that by calling the script “generate_tfrecord_n.py” will generate less data to train for the tensorflow engine .
However , I still get above 93% of CPU load (see enclosed snapshot) although i reduced the training data as mentioned in the following quote:
"
If the scripts gets killed, it means that you chose a batch_size that was too big for the processing power you have. Lower it in the ssd_mobilenet_v1_coco.config and try again. Also, using a lot of training images might kill the process as well, so again, remove some of the images, redo the previous steps, and try again.
"
Where can i find ssd_mobilenet_v1_coco.config ??
Any hints ? what Am i doing wrong ??? How can i reduce the CPU load in order to check if the toolchain works accordingly (only for learning sake )
Thanks in advance